

Most product managers track sprint velocity, feature completion, and release dates. What they don't track? The 15-20 hours per release spent in emergency coordination meetings because marketing built campaigns for features that engineering quietly deprioritized last minute. Or the customer success team finding out about breaking changes through customer complaints instead of a heads-up.
The cost compounds fast. A fintech startup I worked with calculated they were burning around $42,000 per quarter on coordination overhead alone — product managers spending nearly a third of their time firefighting launch issues instead of building out the next quarter's roadmap. Their mobile team shipped a payment flow update that broke the web team's checkout process. Nobody caught it because release coordination lived across 14 different Slack threads.
Why traditional release planning breaks at scale
The standard approach looks deceptively simple. Engineering owns the release calendar. Product writes requirements. Marketing gets a heads-up two weeks before launch. Support hears about changes during all-hands.
That works fine with one product team, one engineering squad, and releases every two weeks. It completely falls apart once you hit three or more teams shipping continuously.
Here's what a typical week looks like in most organizations around 40-50 people:
Engineering Team A ships a backend API change on Tuesday. Mobile Team B's feature depends on that API but they're releasing Thursday. Web Team C built their entire sprint assuming the old API stays live until month-end. Marketing scheduled customer webinars showcasing features that won't actually ship for another sprint because they heard "end of month" in a standup three weeks ago.
The breakdown accelerates when teams use different tools. Engineering tracks dependencies in Jira. Product manages roadmaps in ProductPlan. Marketing runs campaigns from Monday.com. Customer Success documents known issues in Notion. Every tool becomes its own isolated version of the truth.
A marketplace platform I consulted for shipped 12 breaking changes in Q3 alone — changes that directly impacted partner integrations. Their partner team only found out when angry emails started flowing in. The engineering team had documented everything perfectly... in an internal wiki nobody else knew existed.
The compound effect of missing dependencies
Dependency tracking isn't about drawing lines between features on a Gantt chart. Real dependencies hide in places most teams never think to document.
Eliminate product chaos and align your team.
Itemyly helps you plan, prioritize, and track every product milestone seamlessly.
- Centralized roadmap management
- Stakeholder collaboration
- Release tracking & analytics
No credit card required
Take a typical e-commerce platform release. The checkout team ships a new payment provider integration. Seems straightforward — one team, one feature. But the actual dependency web touches:
The fraud team needs new rules for the payment provider's risk signals. The data team needs ETL pipelines updated for transaction reporting. The mobile team needs SDK updates pushed through app store review cycles. Accounting needs reconciliation logic adjusted. Customer support needs macros updated for payment failure scenarios.
Miss any of these and you're looking at partial outages, data inconsistencies, or support tickets that nobody can actually resolve.
The real damage usually shows up post-release. A B2B SaaS company pushed what they considered a simple pricing tier update. They mapped dependencies between billing and subscriptions carefully. What they missed: their onboarding flow had hardcoded pricing tiers for demo accounts. New trials couldn't complete signup for six hours. The fix took 20 minutes. Rebuilding customer trust took months.
Building pre-release gates that actually prevent disasters
Most teams confuse approval workflows with quality gates. Getting three people to click "approve" in Jira doesn't prevent bad releases. You need operational checkpoints that verify readiness across every impacted system.
Start with technical readiness gates
Engineering gates should verify more than "code complete." A functional cross-team release plan needs confirmation that:
Database migrations run successfully in staging with production-scale data. API contracts match what consuming teams are actually using — not just what's documented. Feature flags work correctly across all environments. Rollback procedures have been tested with an actual rollback, not just written down. Performance benchmarks hold under load.
One platform engineering team baked this into their deployment pipeline — releases literally couldn't proceed until automated tests confirmed downstream services still functioned. They went from three or four breaking changes per quarter to zero in six months.
Add operational readiness checkpoints
Technical readiness means nothing if operations isn't prepared. Operational gates need to verify:
Support documentation exists and the support team has confirmed they actually understand it. Customer communications are drafted and reviewed by teams who'll handle responses. Internal training is complete for anyone touching the feature. Monitoring alerts are configured and tested in staging. Runbooks are updated with new troubleshooting steps.
The key difference: these aren't checkboxes. Each gate requires evidence. Support doesn't just say "we're ready" — they demonstrate handling a mock escalation using the new documentation.
Require a demonstrated rollback on staging before marking technical gates as complete.
Here's a visual workflow of the pre-release gate process.
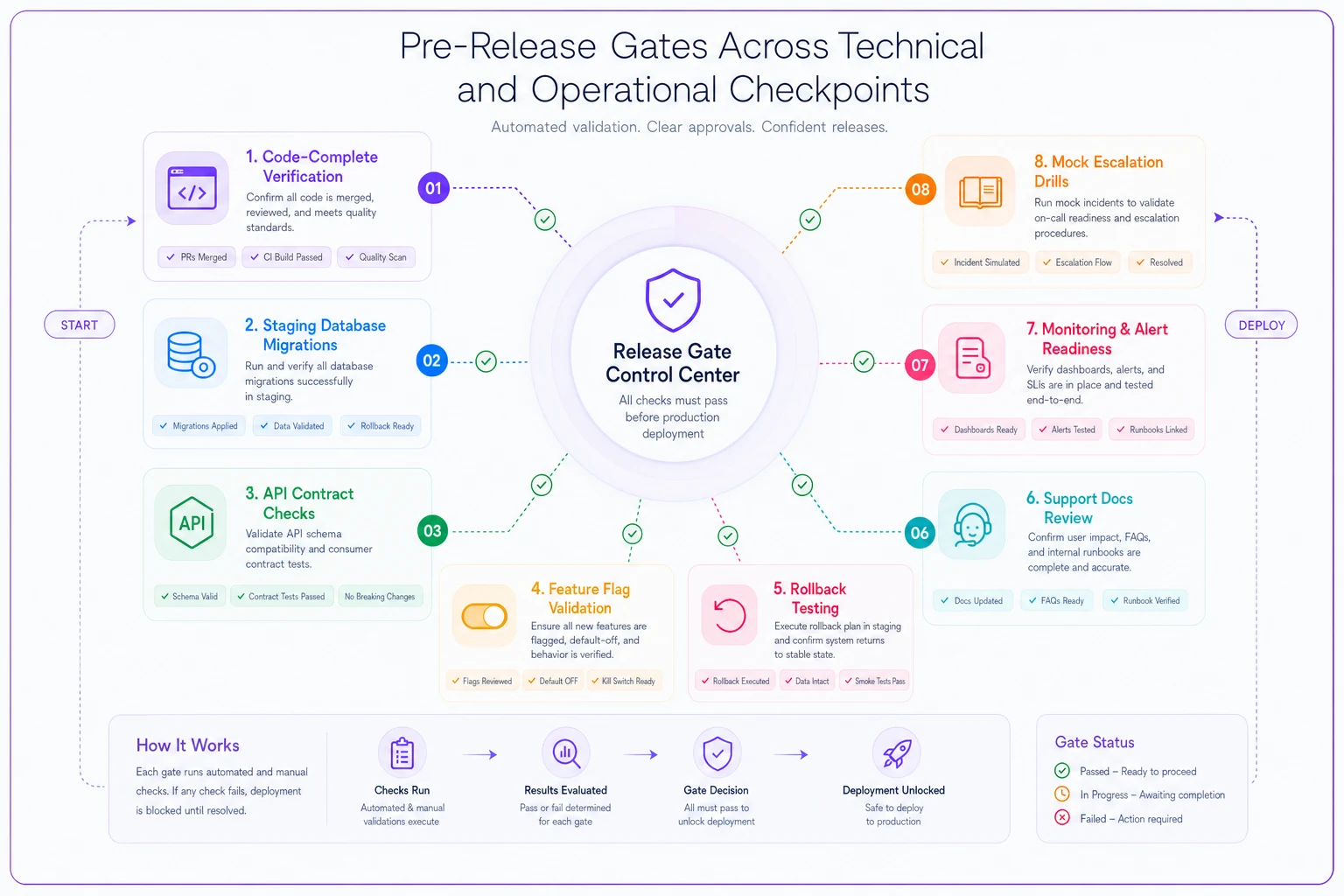
This diagram shows how automated gates and operational checkpoints fit into a single pre-release workflow.
Stakeholder notification matrices that prevent surprises
Standard notification approaches fail because they treat all stakeholders the same. "We'll send an email to everyone about the release." That email gets buried under 47 other release notifications that week.
Effective notification requires segmenting by impact level:
Critical stakeholders need synchronous communication. If the release breaks, these people field the calls. They get calendar invites for release windows, pre-release briefings, and designated points of contact during deployment.
Affected stakeholders need detailed async updates. They won't get customer calls, but their day-to-day work changes. They receive documentation 72 hours before release, recorded walkthroughs of changes, and clear migration guides for their workflows.
Informed stakeholders just need awareness without the noise. A single summary 24 hours post-release works — what shipped and where to find details if needed.
| Stakeholder Group | Notification Timing | Channel | Content Required |
|---|---|---|---|
| Customer Success Managers | T-5 days | Dedicated Slack channel + Email | Full changelog, talk tracks, known issues |
| Enterprise Customers | T-3 days | Account manager calls | Customized impact assessment |
| Integration Partners | T-7 days | Technical documentation site | API changes, deprecation timeline, migration guides |
| Internal Operations | T-1 day | All-hands announcement | Feature overview, support paths |
Support ticket volume for new releases dropped around 60% after implementation. Not because releases got better — because people knew what was coming.
Launch fallback decisions before you need them
Every release plan includes rollback procedures. Almost none include clear criteria for when to actually use them.
Teams waste critical minutes — sometimes hours — debating whether an issue is "bad enough" to rollback while customers are actively suffering. You need predetermined thresholds that cut through the paralysis.
Define your abort criteria upfront
Abort criteria should be specific and measurable:
-
Error rates exceed 5% for more than 5 minutes
-
More than 3 P0 customer reports
-
Core business metrics drop more than 15% from baseline
-
Any data corruption detected
-
Payment processing failures exceed 1%
These aren't suggestions — they're automatic triggers. Hit the threshold, execute the rollback. Debate the decision in the retrospective, not during the incident.
Create graduated response playbooks
Not every issue requires a full rollback. Build graduated responses for different severity levels:
Level 1 (Minor Issues): Toggle specific feature flags off. Keep the release live but disable problematic components. Fix forward within 24 hours.
Level 2 (Significant Impact): Partial rollback of affected services. Keep stable features live. Communicate workarounds to impacted users. Fix required within 4 hours.
Level 3 (Critical Failure): Full rollback to previous version. All-hands response team activated. Executive communication triggered. Post-mortem required within 48 hours.
A subscription management platform learned this the hard way. They spent three hours debating whether to rollback a billing update while $400K in renewals failed to process. Now they have a clear rule: any billing failure over $10K triggers automatic rollback, no discussion needed.
Post-release measurement beyond vanity metrics
Most teams measure release success with deployment metrics — did it ship on time, did it stay up, did we hit velocity. These tell you almost nothing about actual release quality.
Real post-release measurement tracks operational impact:
Cross-team coordination overhead: Hours spent in emergency meetings, unplanned syncs, and firefighting. One team tracked this and found they were burning 40 engineering hours per release on coordination that should've happened during planning.
Downstream impact time: How long before all affected teams adapt to changes. If customer success needs two weeks to update their workflows after every release, that's a coordination problem, not a training problem.
Hidden failure costs: Support tickets from undocumented changes. Customer churn from surprise breaking changes. Partner integration failures from missed dependencies.
Build continuous improvement triggers
When support tickets exceed 20 per release → Mandatory support team involvement in release planning
When coordination overhead exceeds 20 hours → Release planning process review required
When rollback rate exceeds 10% → Automated testing expansion for common failure points
When partner complaints exceed 3 → API versioning strategy review
Remediation patterns that prevent repeat failures
Post-mortem documents pile up in wikis nobody reads. The same failures repeat quarter after quarter because teams treat incidents as isolated events rather than systematic patterns.
Effective remediation requires pattern recognition across releases. A payments company analyzed six months of release incidents and found roughly 70% traced back to three root causes:
-
Timing misalignment — Teams assumed others would release simultaneously when they actually shipped days apart
-
Configuration drift — Staging environments didn't match production configuration, hiding issues until deployment
-
Communication gaps — Critical information lived in team-specific channels that cross-functional stakeholders couldn't access
Instead of writing six post-mortems all saying "communicate better," they built systematic fixes:
For timing issues: Created a unified release calendar with automated notifications when dependencies shifted. No more assumptions about when other teams ship.
For configuration drift: Built configuration validation into their CI/CD pipeline. Releases couldn't proceed if staging didn't match production settings.
For communication gaps: Established single source of truth release channels with required stakeholder participation. Miss three release syncs and your team's deployments get blocked.
The operational cost of ad-hoc coordination
Poor cross-team release planning has a pretty predictable operational cost profile:
Product managers spend 8-12 hours per sprint in reactive coordination. Engineering leads burn 5-6 hours weekly on cross-team debugging that proper planning would've prevented. Customer success handles 20-30% more tickets from preventable release issues. Marketing wastes somewhere between $3K-8K monthly on campaigns for features that ship late or differently than communicated.
Add it up across a 50-person product organization and you're typically looking at $300K-400K annually burned on coordination inefficiency. That's two or three full-time salaries spent managing preventable chaos.
The solution isn't more meetings or better documentation. It's building systematic orchestration so coordination becomes automatic rather than reactive.
Making cross-team releases predictable
Teams that consistently ship without chaos don't necessarily have better engineers or more experienced PMs. They have better systems for orchestrating releases across organizational boundaries.
That means building release coordination into your operational fabric — not treating it as an add-on process. Your release planning needs the same rigor as code review. Your dependency tracking needs the same automation as your deployment pipeline. Your stakeholder communication needs the same consistency as your sprint ceremonies.
A proper cross-team release plan isn't about perfect documentation or elaborate approval chains. It's about creating systematic checkpoints that catch misalignment before it becomes customer impact. When every team knows their dependencies, understands their notifications, has clear fallback criteria, and measures real operational impact, releases stop being fire drills and start becoming predictable.
The difference between teams that ship chaos and teams that ship consistently isn't talent — it's whether they've built systematic orchestration or are still relying on heroic coordination efforts every single time.
Ready to elevate your product management?
Join 2,000+ product teams using Itemyly to accelerate delivery, improve alignment, and build better products.